ChatGPT横空出世
WISDOM
近期,ChatGPT火爆全网,马斯克、库克都对它赞美有加,比尔盖茨甚至认为它不亚于互联网的诞生,具有划时代的意义。
它仅仅用了2个月,月活用户就达到1亿,打破了此前TikTok保持的9个月的纪录。
它能聊天,能翻译,能做题,能考试,能作曲,能撰写文案,能编代码,能写论文,能构思小说,能写视频脚本......能做很多很多事,而且比很多人做得好。
而且它现在只是初代,后续还会不断更新迭代。人工智能领域专家普遍认为,未来20年内,此类型的人工智能,将取代全球一半工作岗位。
那么,律师的工作岗位会被取代吗?

图片来源于网络
ChatGPT可自我学习
WISDOM
要回答这个问题,首先要了解它是怎样工作的。
神经科学近十年来有一个重大发现,“预测”是大脑非常底层、非常重要的一种信息加工方式。大脑每天通过外界输入的电信号,微调神经元之间的连接,优化神经网络,使它能更好地反映外部世界。当接触到新信息时,大脑会根据已有的心智模型对未来进行推断,“预测”我们可能会遭遇什么,需要作出什么反应,可能会引发什么后果,将预测的结果和实际发生的情况进行对比,发现不同,从不同中进行学习、修正,让自己将来可以预测得更准确。预测得越准确说明认知水平越高。
这种由即时的环境引发的高级的联想记忆功能,就是“预测”。ChatGPT的基座模型就是以“预测”理论为指导设计训练模式。与人类大脑不同的是,喂给ChatGPT的不是真实生活中的各种刺激,诸如声音、图像、气味、语言等等,而是海量的文本,它以海量文本信息为基础,根据以前看到的字,不断地预测下一个字。所以,它和人类有很多相似的地方,有非常强的自然语言理解能力,像一个人类助手,可以用自然语言和它交流,给它布置非常灵活的任务。但同时,由于摄入信息的种类受限,导致它在需要深度理解的工作上无法胜任。
ChatGPT无法做到准确与严谨
WISDOM

图片来源于网络
1
ChatGPT无法判断原始数据真假,
默认数据都是正确的
如果“输入”是错的,怎么得出正确的结论呢?
“皇帝的新装”之所以荒诞,是因为故事里的所有人都无条件相信:新衣服具有鉴别蠢蛋和不称职者的功能,所有的一切都发生在这个说法为“真”的前提下。但凡对这个前提产生质疑,就不会有这么经典的故事。
置身事外,每个人都能看出它的寓意和荒诞。然而,置身事内,切换到自己参与的网络世界,恐怕就难以如此清晰地洞见。网络上的信息泥沙俱下,无论获取到何种信息,ChatGPT都会默认为“真”,在此前提下开展分析和反馈。那么,对于深层次的问题,我们敢相信ChatGPT的解决方案吗?
原始数据的真假问题,是ChatGPT无法避免的软肋,而“辨别”真假,是目前的模型无法做到的。

图片来源于网络
2
ChatGPT获得数据受限
全球越来越重视信息安全、数据安全,甚至将其上升到事关国家安全的高度,在这种大环境下,基于巨量网络数据信息的ChatGPT,它所能获得的基础数据、用以分析的原始数据,其真实性、全面性又将如何呢?
它能够获得的,绝对不是人们想象中的、公正客观、不偏不倚的中性数据,而是事先设定好的、充斥着特定偏好、特定价值观的数据。ChatGPT的自我学习能力根据数据量而发展,当它的原始信息源受限时,它能够“学习”到多少,最终又能给出什么样的“解决方案”呢?
3
ChatGPT缺乏对非语言信息的识别
人与人之间的沟通,除了语言沟通,还包括非语言沟通,如肢体语言、面部表情、眼神、语气等等。美国传播学家艾伯特·梅拉比在《非语言沟通》一书中发表了一组数据,信息的传递=7%语言+38%声音+55%表情和动作。如,在朋友家做客,不知不觉已经到晚上十点了,不好意思下逐客令的主人频繁看表,虽然一句话也没说,但客人也知道是什么意思,这就是非语言信息的表达效果。缺乏对非语言信息的识别,会导致沟通无法持续和深入。

图片来源于网络
ChatGPT获取的数据,全部都限于文本信息,即“内容”,而缺乏全部“非语言”信息。所以它在和人类对话时,更多停留在交换信息的层面,顶多能识别人类简单的意图,而无法识别人类的复杂意图,导致无法深入沟通。指望AI解决问题,就好像生活中与一个怪人合作,你能问他一些问题,他也能给你百科全书式的答案,但仅此而已。
所以,需要与人进行大量沟通、互动的工作,就是ChatGPT无法胜任、也不可能取代人类的工作。
ChatGPT无法做价值判断
WISDOM
科学家渐渐发现,人类大脑的理性决策,其实都有情绪的参与。美国神经科学专家达马西奥在他的著作《笛卡尔的错误》里,重点讲了两个病人,一个是因为工作,头被钢筋穿过,另外一个是因为肿瘤,大脑受损伤。当这两个人恢复健康之后,他们跟常人没有什么不同,身体没有不同,智商没有不同,可以工作,可以结婚,唯一的问题就是情绪非常不稳定,而与之相伴的,就是他们的判断能力出现了问题。他们可以分析,但无法做选择,无法判断哪种选择对自己更有利。后来,他用先进的设备在很多人身上做了实验,无一例外地在他们身上看到决策缺陷与情绪和感受的缺乏是同时出现的。
所以,他推断:情绪与决策如影随形,人是不能脱离情绪,来进行所谓理性决策的,人的所有决策,看似是理性选择,事实上都是情绪参与的结果。

图片来源于网络
人类对于复杂问题的价值判断,更是饱含了人类特有的情怀、伦理、道德等主观因素。而ChatGPT,哪怕拥有远超人类的海量信息,也无法拥有生命所特有的“情绪”。超级理性计算的结果,即使逻辑上正确,也未必是正确的判断和决策。
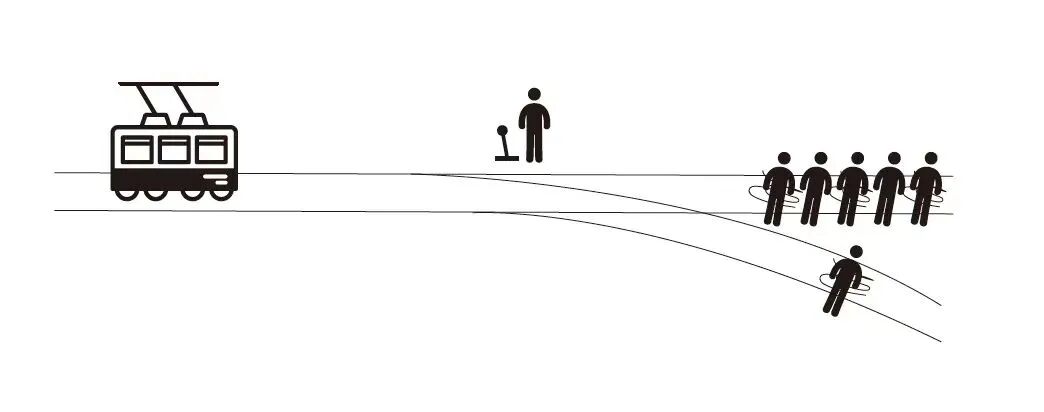
比如,著名的“电车难题”,不仅涉及哲学、伦理学,还涉及刑法学:一个疯子把5个无辜的人绑在电车轨道上,一辆失控的电车朝他们开来,很快就要撞上他们。你可以拉一拉杆,让电车开到另一条轨道上,然而问题在于,那个疯子在另一个轨道上也绑了一个人。面对这种情况,你是否会拉杆呢?
生命是有价,还是无价?生命可以比较吗?一个人的生命和五个人的生命,谁更有价值?进一步,假如其中有你的亲人,或者仇人,假如其中有人对社会贡献非常大,那么,你又怎么选择呢?如果让ChatGPT去进行这种价值判断,逻辑起点在哪里?人类能把这种价值判断,交给ChatGPT去做吗?
图片来源于网络
法律领域,ChatGPT的可为和不可为
WISDOM
1
技能分类,ChatGPT能力各有长短
虽然ChatGPT拥有超级强大的知识库,但“学到知识”和“解决问题”,是完全不同的两回事。解决问题的技能,分为“程序性”技能和“理解性”技能,ChatGPT擅长前者,却难以突破后者。
程序性技能,是基于程序性知识,以需要遵循的序列、步骤、流程的形式出现。典型的程序性技能有软件开发流程,PPT制作,社群日常运营等等。一般只要按一定的程序步骤重复,最后都能达到熟练。这正是ChatGPT的长项。
理解性技能,是基于概念性知识,强调对知识理解和使用的深度,强调认知的广度和深度。对于理解性技能,信息层面的学习,甚至交流和讨论都只占很小一部分,最重要的是需要在行动层面去执行、落地和实践。对于理解性技能,“纸上谈兵”与“实战”就相去甚远,如果当做事实性知识来记忆、处理,必然是掌握不好的。而ChatGPT还只能将它当做事实性知识来处理,这正是它的弱项。

图片来源于网络
2
法律纠纷高度个性化,
ChatGPT无法取代律师
法律技能,恰恰就是理解性技能。
首先,律师的工作对象——法律规则,本身就是调整人与人关系的社会规则,随着人类思想与活动的变化而变化,总会有层不出穷的新的交易、新的社会活动,突破过去的规则,很难用过去的规则来进行价值判断,需要创设新的规则来适应新的社会关系。即,法律规则总是滞后于人类社会活动。
而ChatGPT则正好与之相反,喂给它的全部都是过去的规则,在社会动态发展过程中,必然无法适用于新类型、新特点的交易和社会关系。单靠ChatGPT决策,是一定会出错的。
其次,法律规则是高度抽象的,法律纠纷都高度个性化,难以直接套用,需要在“规则”与“事实”之间反复比对,同时还需要考虑很多非法律因素。具体到案例层面,ChatGPT擅长的是“规则”,但不擅长“运用”,难以做到比对、综合评估,更难以判断非法律因素的具体影响。

图片来源于网络
第三,律师首先解决“是不是”的问题,再解决“怎么做”的问题。
了解案情是分析案件的起点。我们经常会发现,客户口头告诉我们的案情,跟证据材料反映的案情,差距非常大,甚至可以截然相反。这是因为,同一堆材料,专业人士评估出来的要素、要点,跟普通人的直觉是完全不一样的。所以律师的工作首先是判断:客户说的,是这么回事吗?首先解决“是不是”的问题,才能开始后面的环节。
ChatGPT的起点,是客户的“提问”,而它无法独立判断,这个“起点”本身是否符合事实。
3
即使无法取代律师,
ChatGPT也能成为律师强大的助手
ChatGPT之父奥特曼想做的,是更高阶的通用人工智能AGI,AGI重点不在于掌握某一种难得的技能,而是拥有学习的元能力,只要人类需要,就可以往任何技能方向发展并精通,帮助人类解决问题。研发ChatGPT,仅仅只是迈向AGI的第一步。
法律纠纷的高度个性化决定了:要解决问题,无论是咨询还是案件,都需要一对一,但这样一来,业务就不可能批量化。
图片来源于网络
如果在法律细分领域,出现此类人工智能,那么将大大地提高律师的工作效率。在纠纷解决方面,律师可以借助强大的ChatGPT,实现基础的法律检索与研究工作;在法律咨询方面,律师也可以借助强大的ChatGPT,实现咨询业务的一对多,甚至一对无数,律师要做的,就是设置足够准确的模型,并根据ChatGPT得到的反馈,调整和修正参数,调整和更正错误,使它越来越智能化,最终可以同时面对千千万万的用户。
最后,笔者认为,即使ChatGPT能取代人类很多岗位,但应该也如同过去几百年的历史一样:技术变革消灭了很多岗位,同时也创造出很多新的需求和岗位。真正的挑战是:新科技的发展会将人类引向何方?人类根据已有的经验很难做出准确判断。站在当下的节点,我们仍然以人类为主体,去思考人工智能怎样成为更好用的工具,焉知未来人工智能的迅猛发展和大规模应用,会不会从根本上撼动人类的主体性?这不是哪一些行业、哪一些岗位、哪一些人群独有的问题,而是全人类共同面临的挑战。
律师介绍

冯颖琼 中共党员
维思德律师事务所执业律师
清华大学 法律硕士
主要业务领域为经济纠纷、企业合规与风控、数据与网络安全、个人信息保护
座右铭:学以致用用有所成
往期 · 推荐
编辑:冯颖琼
校对:刘晨卉